文章來源:火幣區塊鏈研究院
報告發布時間 2018 年 9 月 6 日
作者:袁煜明、胡智威
摘要
本文首先對 BFT 類共識協議按照改進思路分爲 3 大類進行綜述性概覽:
- 針對無拜占庭錯誤場景優化的協議,包括 PBFT、Zyzzyva 等等
- 針對拜占庭錯誤場景優化的,包括 Aardvark、Primer 等等
- 爲公鏈應用而優化的協議,包括 DPoS+BFT、Zilliqa 等等
本文還選用 PBFT、Zyzzyva、Zilliqa 協議,編寫程序進行實測,主要得到以下結果及技術指導建議 :
1、Zyzzyva 和 Zilliqa 等協議的網絡通訊量確實比 PBFT 降低很多。
2、調整 PBFT 檢查點週期對性能沒有太大影響;而調整批量大小則會較大程度上提高吞吐量指標、縮短共識時間,不過同時也會加大消息量對網絡造成壓力。
3、Zyzzyva 在其客戶端足夠的情況下,增加批量數會對吞吐量和共識時間等性能指標均有較大提升。
4、雖然增加批量數對 Zilliqa 等協議都有促進效果,但這也會增加帶寬佔用。在設計共識協議時應綜合考慮性能目標與網絡帶寬等實際情況。
報告正文
1. 引言
共識協議被許多人視爲是區塊鏈項目的核心。無論是對區塊鏈平臺的交易處理能力、擴展性影響還是對通證經濟的激勵模型設計,共識協議都會產生很大影響。
共識協議從大的方面可分爲自比特幣誕生以來產生的 PoW 等中本聰共識協議和拜占庭容錯(BFT)類共識協議這兩大類協議。其中,在計算機科學的分佈式系統研究領域已較多研究的 BFT 類共識協議近年來被越來越多的應用於聯盟鏈平臺。與此同時,也有越來越多的研發工作嘗試將 BFT 應用於公鏈平臺。
我們在本文中對 BFT 類協議進行了綜述性概覽分析,並從改進思路上將現有 BFT 類共識協議分爲 3 大類:針對無拜占庭錯誤場景優化的協議、針對拜占庭錯誤場景優化的協議以及爲公鏈應用而優化的協議;另外選用了 PBFT、Zyzzyva、Zilliqa 協議,編寫程序並運行後得到實測對比結果,對共識協議的具體設計提供一些技術性指導建議。
2. 主要結論
經過研究與測試分析,我們得到以下主要結論及技術建議:
1、Zyzzyva 和 Zilliqa 等協議的網絡通訊量確實比 PBFT 降低很多。
2、對 PBFT,調整檢查點週期對性能沒有太大影響;而調整批量大小則會較大程度上提高吞吐量指標、縮短共識時間,不過同時也會加大消息量對網絡造成壓力。
3、Zyzzyva 在其客戶端足夠的情況下,增加批量數會對吞吐量和共識時間等性能指標均有較大提升。
4、雖然增加批量數對 Zilliqa 等協議都有促進效果,但網絡中消息量也會增加。在設計共識協議時應綜合考慮性能目標與網絡帶寬等實際情況。
3. 共識問題及 BFT 協議簡介
3.1. 一致性問題及原理
計算機世界早已從「單機版」進入了「大型多人在線」的時代,區塊鏈的誕生與發展更是讓這一特性得到了充分的體現。這個過程中不可避免的產生了多個計算機之間如何達成一致的問題。常見問題包括:
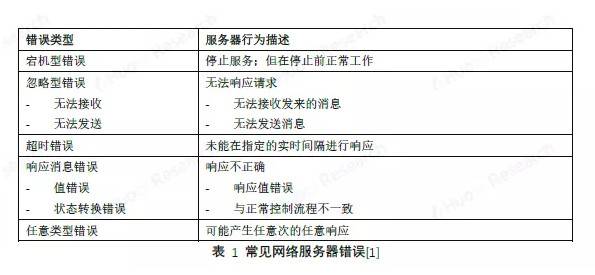
在已經大規模投入使用中的分佈式數據庫系統環境中,有可能存在很多的宕機錯誤。根據 CAP 原理 [2],Paxos 和 Raft 協議被設計爲在犧牲一定可用性的情況下,解決在節點服務器可能宕機問題的協議 [3]。
然而這些協議在區塊鏈領域內還不能直接使用,因爲還有其他更多在區塊鏈領域內可能出現的錯誤。在表 1 中這種任意類型錯誤都可能發生的場景中,服務器有可能產生原本不應該輸出的內容,系統要做好最壞情況的準備。例如,當一個服務器向不同的服務器發送截然相反的消息時,那麼僅可處理宕機錯誤 Paxos 協議就無能爲力了。
這種類型錯誤,也被稱爲拜占庭錯誤,最早由 Pease 和 Lamport 在上世紀 80 年代通過拜占庭將軍問題進行描述和分析 [4][5]。
因此相較於分佈式數據庫,區塊鏈的對於一致性問題的設計和實現要更爲複雜,這也是爲什麼區塊鏈不只是一個簡單的分佈式數據庫的原因之一。
3.2. BFT 共識原理及流程簡介
Lamport 等人在其經典論文 [4] 中除了提出拜占庭將軍問題外,也提供了兩種解決辦法 [6][7]。
第一種爲「口頭消息」的 OM(m) 協議,即除了鏈路上可使用加密安全保障外,不允許使用任何的加密算法。該協議需要兩兩之間遞歸的傳遞大量消息,因此消息複雜度很高,爲指數級,不太具有可實際操作性。但這一算法仍有其很高的價值,首先是爲「實用拜占庭容錯」(Practical Byzantine Fault Tolerance)這一多項式級別複雜度協議的誕生做了一個鋪墊;另外,其 1/3 容錯節點數量也被證明爲是該類算法的理論上限。
而第二種爲「加密消息」的 SM(m) 協議。該算法與第一種不同之處在於使用簽名算法。每個節點都能產生一個不可僞造的簽名,並可由其他節點進行驗證。當收到消息後,節點會通過簽名來判斷及驗證該消息是否已收到過。最終不再收到消息後,消息共識結束。它同樣假設是在一個同步網絡內進行;另外,簽名身份體系信息需要在網絡運行前確定,較難實現擴展。Vitalik 近期在其博客上發佈了一篇名爲《一個 99% 容錯共識的指南》[8] 就是根據這一協議在區塊鏈實際場景中所作的適應性改造探索 [9]。
3.3. 技術思路分析
與從比特幣系統中衍生出的中本聰共識不同,BFT 類協議基於節點間傳遞消息對網絡中提案達成共識。因此一般來說消息複雜度較高,而且節點的加入和退出過程需要進行特別處理,但一旦達成共識則形成確定性結果,而不是中本聰共識的概率上的最終一致。
因此基於以上特性,BFT 類共識目前在金融場景以及聯盟鏈場景中應用的更多。不過隨着研究的探索推進,一些可在公有鏈場景下使用的 BFT 共識也正在不斷研發出來。
4.BFT 類共識概覽
我們在已有 BFT 類共識分類 [10][11] 的基礎上,繼續對目前 BFT 協議進行了梳理。因爲 BFT 協議中的無論是口頭協議還是書面協議都不夠「實用」,很難在實際場景中直接運用。因此後來學術界和業界對 BFT 協議有了大量的改進。按照改進思路的不同,這些協議主要可分爲以下 3 大類方向:
1)針對無拜占庭錯誤場景進行優化
2)針對拜占庭錯誤場景進行優化
3)爲公鏈應用而做的優化
4.1. 針對無拜占庭錯誤場景進行優化
此場景假設大部分情況下,網絡中的節點運行都正常,拜占庭錯誤並不經常出現,因此可對這種節點均正常情況下的共識機制進行簡化或優化。
下面我們根據不同的優化方法,對這些協議進行分項介紹。
4.1.1. 基於協約的方法
對 BFT 協議最爲經典的改進主要是以 PBFT 爲代表的基於節點協約一致(Agreement)的方法。該類協議通常會有一個主節點作爲網絡中的樞軸。比其他節點相比,主節點在共識過程中會發出最主要的作用,但通常也會成爲系統性能的瓶頸。因爲主節點需要將客戶端發來的請求排序後發送給所有的備節點。所有節點通過互相通信後達成一致,實現安全性(Safety);大多數協議中所有節點也會向客戶端回覆響應,實現活性(Liveness)。該類協議通常需要 3f+1 個節點來實現對 f 個拜占庭節點的容錯。
實用拜占庭容錯(Practical Byzantine Fault Tolerance. 簡稱 PBFT)[12] 是早期對其進行的改進,將 BFT 的消息複雜度從指數級降低爲 O(n^2) 級別,即具備了可實際使用的條件。

PBFT 協議將共識過程分爲了 5 個階段(如果不算與客戶端交互的階段,則可視爲 3 個階段):
1) Request 階段是客戶端發送信息;
2)在 Pre-prepare 階段,主節點接到消息對其簽名並分配一個唯一的序號 n 並將該消息發送給其他節點;
3) Prepare 階段:所有備份節點收到主節點發來的 PRE-PREPARE 消息後,將一個包含當前視圖號 v、消息序號 n、消息摘要的 PREPARE 信息發給所有其他節點。如果節點收到了 2f 個以上的 PREPARE 消息後則進入到下一階段並且該消息處於 Prepared 狀態。
4) Commit 階段:每個節點廣播一個保護當前視圖號 v、消息序號 n 的 COMMIT 消息。當節點收到 2f 個相同的 COMMIT 消息並且小於序號 n 的消息都已被執行,那麼當前消息會被執行並被標記爲 Committed 狀態。
5) Reply 階段:所有節點將執行結果返回給客戶端。
除了以上階段流程外,協議運行過程中還涉及到幾個重要概念:
1)水位:每個節點在運行協議時會設置一個處理消息的窗口,消息序號在這個區間內的時候纔會被處理,例如最小序號設爲 h、最大序號爲 H。
2)檢查點(Checkpoint):在運行提交過程中所有已處於已準備好(Prepared)和已提交狀態(Committed)的信息會被記錄在內存中。節點會定期(每執行 k 個請求後)記錄一個穩定的檢查點並截斷記錄,即每執行 k 個請求後,會將水位 h 和 H 提高 k 個單位。
3)視圖切換(View Change):但是當節點發現對某個消息的等待超過一定時間後,則認爲是主節點失效,會發送視圖切換(VIEW-CHANGE)消息並開始視圖切換的過程。
4)批量(Batch): 實際執行中會採用的一些優化改進技術,例如批量方式,即實際程序並不是對單個提交來每次運行協議,而是會在以集合形式同時在網絡中處理,並通過設置批量大小(Batch Size)的方式來控制處理消息的數量。
在設置了以上運行機制後,儘管消息複雜度仍然較高,PBFT 已具備了實際運行的可行性。之後的許多 BFT 類協議均在 PBFT 協議基礎上進行改進,並將 PBFT 作爲研究對比的基準對象。
Chain 協議。Chain 協議 [13] 採用了一個和其名稱很相似的鏈條式傳播路徑 [14]。從主節點開始,每一次傳播時即加入該節點的摘要信息。當客戶端較多時,Chain 通常會比 PBFT、Zyzzyva 等吞吐量更高。

Ring 協議。Ring 協議 [15] 使用環形拓撲方式來傳遞消息,即每個節點都有消息的上一個發送者和下一個接收者,以此方式來降低對部分節點分配更多工作而形成的性能瓶頸問題。對有無錯誤的不同場景,Ring 分別採用兩種運行模式:快速模式(Fast Mode)和彈性模式(Resilient Mode),並採用 ABSTRACT 框架進行切換 [14]。

BFT-SMaRt 協議。BFT-SMaRt[16] 與 PBFT、UpRight[17] 類似,但增強了可靠性、模塊化程度、同時還提供了靈活的編程接口。
4.1.2. 基於 Quorum 的方法
Quorum 機制是一種分佈式系統中常用的機制,用來保證數據冗餘和最終一致性的投票算法。其主要思想來源於抽屜原理,常用於分佈式系統的讀寫訪問控制 [18]。
該類共識協議不需要節點間相互通訊,而是由節點直接執行並響應客戶端發來的請求。當受到足夠數量的響應後,客戶端纔會將結果最終提交。但是當出現拜占庭錯誤場景時,通常會花費較大的代價來解決。另外,由於缺少對請求的排序機制,Quorum 方法無法處理有競爭(contention)的情況。
Q/U 協議。Q/U 協議(Query/Update)[19] 是一個典型的基於 Quorum 的協議。Q/U 沒有主節點來爲請求排序,而是由客戶端直接向節點發送請求並由節點反饋結果。它需要 5f+1 個節點來對 f 個拜占庭節點容錯。
HQ 協議(Hybrid Quorum)[20] 是另一個較爲早期和著名的共識協議。正如其名稱,HQ 綜合參考並優化了 Q/U 協議和 PBFT 協議:只需要 3f+1 個節點進行容錯,並針對沒有競爭的情況簡化了 PBFT 節點間通訊。當沒有競爭情況下,共識主要分爲兩個階段:第一階段是客戶端發送請求並收集節點的狀態信息;當收到結果表明 2f+1 個節點狀態相同且可以執行請求後,開始第二階段信息發送、由節點執行請求。而如果發現有競爭,則採用類似 PBFT 的解決過程,性能也退化爲和 PBFT 類似。

Quorum 協議也是基於 Quorum 機制的一個共識協議 [14],主要沒有客戶端競爭的非異步網絡而進行設計,只需要 3f+1 個節點進行拜占庭容錯。當沒有錯誤產生時,Quorum 協議的傳播路徑和 Q/U 類似,節點獨立執行請求並自己維護一個執行歷史記錄。當客戶端數量較少時,其吞吐量和延遲等性能指標均比其他 BFT 類共識更好。但其缺點也和 Q/U 類似,無法處理客戶端有競爭的情況 [10]。
4.1.3. 基於 Speculation 的方法
在這類協議中,節點不需要通過需要消耗大量系統代價的 3 階段提交過程即可響應客戶端的請求。採用了更樂觀的策略,節點同意由主節點發出的排序請求並給客戶端返回結果。由客戶端而不是節點來負責考慮一致性問題。如果發現不一致問題,由客戶端負責通知節點回滾至一致狀態。
Zyzzyva 協議。Zyzzyva 是該類中最典型的一個協議 [21]。它需要 3f+1 個節點進行拜占庭容錯。與基於 Agreement 的協議類似,Zyzzyva 中的主節點也是將客戶端發來的請求排序後轉發其他節點。每個節點根據自身歷史記錄來執行請求並將結果反饋給客戶端。客戶端根據節點返回的一致性結果數量分別執行不同的動作。
在沒有錯誤的場景下,Zyzzyva 表現比 PBFT 和 Q/U 等協議要好;但是當有錯誤時,因爲要涉及到和 PBFT 類似的 view change 過程,其性能也會急劇下降。

Zeno 協議。Zeno 協議 [22] 在 Zyzzyva 基礎上進行修改,將原有的強一致性替換爲一個較弱的最終一致性保證。它允許客戶端偶爾忽略其他更新,但是當網絡不穩定時,所有節點的狀態需要進行合併以達成一致。
ZZ 協議。ZZ 協議 [23] 同樣基於 Speculation 機制。因其還採用了分離處理的機制,也可將其歸爲“分離處理一致性與執行請求的階段”的類別,我們將在後續章節繼續介紹。
4.1.4. 基於客戶端的方法
基於客戶端的方法通過避免節點間通信的方式,來避免異常節點對正常節點的攻擊、誤導或延遲。協議完全依賴於這些客戶端的正確性,假設客戶端都沒有異常、是誠實且在宕機時會被外部所感知的。
OBFT (Obfuscated BFT)協議 [24] 是這一類協議的典型代表。它需要 3f+1 個節點進行容錯,但與其他很多 BFT 協議涉及到節點間通訊不同,OBFT 協議中的節點完全不需要關注其他節點並只與客戶端聯繫,因此避免了惡意節點干擾其他正常從而影響系統性能的問題,不過這也帶來了一個較強的假設:必須完全信任客戶端不會作惡。因此該類協議都存在着較難在實際場景中進行應用的問題。

4.1.5. 基於可信組件的方法
因爲 FLP 不可能性原理(即使網絡通訊可靠也無法在任何場景下都能達到共識 [25]),一些協議並不使用傳統的超時等機制而是基於外部的可信組件進行設計。這些組件也需要被認爲是無拜占庭錯誤的,但允許存在宕機等臨時性無法提供服務的情況 [11]。基於以上條件,該類協議可以將容錯節點數量從 3f+1 將爲 2f+1。
例如,CheapBFT 協議 [26]。需要基於一個叫做 CASH 的 FPGA 可信設備,從而降低正常情況下協議對於資源的使用。
4.1.6. 基於拜占庭鎖的方法
拜占庭鎖是拜占庭協議的擴展,通過利用 IO 絕大多數時間裏不會出現競爭的特性來達到降低服務器響應時間、提高吞吐量與擴展性的效果。
這種方法最早由 Zzyzx 協議 [27] 提出,包括加鎖和解鎖兩個部分。加解鎖過程均基於現有拜占庭協議達成對客戶端授權的一致。當授權完成,則獲得鎖的客戶端可直接進行操作,從而去掉了主節點排序、節點間通訊等操作,從而大幅度提高吞吐量。但當有多個客戶端需要頻繁切換時,其性能也會大幅下降,因此該協議較爲適用於客戶端不會頻繁發生變化的情況下。
4.1.7. 基於分離一致性與執行請求的方法
還有一類改進方法是將共識與執行提交的過程分開,因爲執行客戶端請求只需要 f+1 個(當沒有拜占庭節點或者客戶端可驗證結果正確性時)或 2f+1 個節點(當有可能存在拜占庭節點且客戶端不可驗證正確性時),因此可將協議的執行分爲 2 個部分,一部分節點負責一致性共識協議,而另一部分負責執行提交,從而提高吞吐量。
ZZ 協議,通過虛擬化技術 [23] 把節點均正常場景下的執行所需節點數量從 2f+1 降爲 f+1 個。在沒有錯誤場景時,只通過 f+1 個節點來執行請求,其餘服務器在休息狀態;而當執行請求的節點發生錯誤時,客戶端通過虛擬化技術快速啓動更多的節點來執行 [11]。
ODRC 協議也是將執行節點數量將爲了 f+1,但與 ZZ 協議不同,它並沒有採用額外的虛擬化等技術,而是在 BFT 協議過程中的節點達成一致後、執行請求前增加了一個選擇執行節點的階段。該階段根據當前系統狀態,選擇指定數量的節點執行請求 [11]。
4.2. 針對拜占庭錯誤場景進行優化
上面介紹的一類協議均是針對沒有錯誤的場景對 BFT 協議進行簡化而設計,因此當遇到拜占庭錯誤時,這類協議的性能一般都會下降比較多,甚至很難保證系統活性。而另一類協議的改進目的是爲了有效對拜占庭行爲(甚至是一些罕見的行爲)進行容錯,降低系統在有無拜占庭錯誤這兩種場景下的表現差異。主要有以下幾個比較典型的協議。
Aardvark 協議。Aardvark 協議 [28] 的通訊過程與 PBFT 類似,但對許多可能的錯誤場景設計了適應性機制以保證系統的安全性和活性。這些適應性機制包括:對客戶端採用混合簽名等機制來防止客戶端作惡;更爲積極主動的觸發 view change 過程以避免主節點有拜占庭行爲;爲每個節點設計 3f+1 個網絡接口(其中 1 個用於其與客戶端通信,其餘 3f 個用於節點間通訊),以此隔離網絡通道來防止流量攻擊。
Prime 協議。因爲 PBFT 協議中當主節點作惡的 view change 過程對性能的影響較大,即便主節點不進行任何主動作惡,只要在處理排序過程中刻意增加延遲就可以降低系統整體性能表現。Prime 協議 [29] 針對此情況進行了改進,在 PBFT 過程前增加了一個預排序的階段,包括 PO Request、PO ACK、PO ARU 等階段。通過這種分析主節點排序時間的方式,使得所有節點來監控網絡表現。因此主節點必須及時將消息發送給其他節點以避免被替換掉。因爲引入了額外的階段,Prime 在正常場景中的性能要比 PBFT 等協議要低;但在存在錯誤場景中其表現要比其他協議要好。

Spinning 協議。Spinning 協議 [30] 在 PBFT 協議的基礎上,設計用來減輕更換主節點的代價。在正常場景中的,Spinning 通訊過程與 PBFT 相同。不過它沒有 view change 過程,而是通過合併操作的方式來收集不同節點信息來決定之前視圖中的操作是否應在新視圖中執行。
RBFT 協議。Redundant-BFT 協議 [31] 利用目前所流行的多核技術來保障魯棒性。該協議採用與 PBFT 類似的通訊過程,但在 Pre-prepare 階段前增加了一個 Propagate 階段。客戶端首先將消息發送給 f+1 個節點,這些節點在 Propagate 階段相互傳遞消息以此來保證客戶端請求會被所有正常節點接收到。RBFT 執行 f+1 個同一個協議的多個實例,其中每個實例都對應一個在不同物理機器上運行的主節點,不過只有被主實例所排序的請求才會被有效執行。備份實例運行的意義主要在於監測運行性能:當發現主實例運行緩慢時,備份實例將觸發 view change 過程選擇出一個新的主實例。

4.3. 爲公鏈應用優化
傳統 PBFT 及類似協議,其自身的特性導致應用場景有較多限制,例如消息複雜度隨節點數成平方級別上升、主節點容易成爲系統性能瓶頸、節點列表需要提前固定且節點間相互已知。所以在分佈式賬本系統中,更多應用於聯盟鏈或私有鏈場景中。
爲了適應公有鏈場景中的大規模擴展需求,有不少項目進行了有益嘗試,具體方式可主要包括與公鏈共識結合以及基於密碼學機制等兩大類方式。
4.3.1. 與中本聰共識結合
爲了在公有鏈中利用 BFT 類共識的結果可快速得到最終確認等優點,一類做法是將 BFT 類協議與中本聰協議進行結合,以此來取長補短,將 BFT 類共識引入應用到公有鏈的業務場景中。
例如,Elaine Shi 等在 2017 年提出將 BFT 類共識與中本聰共識結合的辦法 [32]:通過 PoW 先選出負責共識的委員會(Commitee);由委員會再進行 PBFT 過程達成共識並出塊 [33]。
DPoS+BFT 協議也是類似的思路。該協議是 BFT 類協議與中本聰協議結合的一個典型代表,被用於 BM 開發的石墨烯 [34]“全家桶”平臺,包括 BitShares[35]、Steemit[36]、EOS[37] 等。通證持有者以投票等方式選出自己支持的“代表”,並由這些代表組成的見證人網絡通過 BFT 的方式進行共識。例如 EOS 中,用戶投票產生 21 個可出塊的“超級節點”,以 BFT 方式共識後輪流出塊,對 1/3 以下的“超級節點”可以容錯。基於該類共識協議的平臺性能較高,且不需要競爭挖礦等,但缺點是略微中心化。
DBFT 協議是 NEO 提出的授權拜占庭容錯協議 [38],和 DPoS+BFT 思路有些類似,是一種通過代理投票實現大規模參與的共識協議。通證持有者可通過投票選出他所支持的“代理”,然後代理再通過 BFT 達成共識。因此它也和 DPoS+BFT 類似,具有快速、擴展性好等特點,但也同樣受到共識節點數量有限、中心化程度太高等質疑。
Tendermint BFT 協議。Cosmos 項目提出了名爲 Tendermint BFT 的一種基於 BFT 的 PoS 共識協議 [39]。它以加權輪詢的方式產生驗證者集合,由選出的驗證者產生共識提議並進行 BFT 過程。因此它也是一種在半同步網絡中使用的確定性算法 [40]。
FBA 協議。Stellar 使用的恆星共識協議(Stellar Consensus Protocol)的背後是一種聯邦拜占庭協議(Federated Byzantine Agreement)。該協議並不是直接把 BFT 和某一箇中本聰共識結合,而是參考了中本聰對比特幣的設計理念。該協議實現一個開放式的節點成員列表,任何人都可以加入。網絡中的每個節點可自行選擇其 Quorum,降低對非理性行爲的容忍程度,所以其性能和可擴展性都較爲突出,但一些拜占庭行爲也可能導致分叉等情況發生,因此節點需要花費不少代價去設置其所信任的節點列表。
還有一些項目在嘗試探索把 BFT 協議引入當前公鏈平臺中,例如 Istanbul BFT (IBFT)[41] 就是通過引入驗證者(validator)並基於 Quorum 機制運行,並被探索用於當前以太坊平臺。
除了狹義的“區塊鏈”方式外,Hashgraph[42] 也可認爲是一種 BFT 類共識與 DAG 結合的協議。它通過 gossip about gossip 降低通信量,並且也是異步的 BFT 協議。
4.3.2. 基於密碼學優化
另一種可運用於公鏈的思路是利用密碼學的方法,包括聚合簽名、可驗證隨機函數、門限簽名等,以達到降低 BFT 類共識的通訊代價、提高共識效率的目的。
聚合簽名
E.Kokoris-Kogias 等在其論文中提出了在共識機制中使用聚合簽名的方法。論文中提到的 ByzCoin[43] 以數字簽名方式替代原有 PBFT 使用的 MAC 將通訊延遲從 O(n^2) 降低至 O(n);使用聚合簽名方式將通訊複雜度進一步降低至 O(logn)。但 ByzCoin 在主節點作惡或 33% 容錯等方面仍有侷限。
之後一些公鏈項目,例如 Zilliqa[44] 等基於這種思想,採用 EC-Schnorr 多籤算法提高 PBFT 過程中 Prepare 和 Commit 階段的消息傳遞效率,並結合分片等優化技術以希望突出改進公有鏈平臺 TPS。
Gosig[45] 也使用該方法,同時還結合了 Algorand 以 VRF 方式選擇“Leader”和多輪投票等方法來儘量降低 Leader 作惡可能性。
可驗證隨機函數
Algorand 的 BA★協議 [46] 使用了另一種密碼學方法——可驗證隨機函數(VRF),以加密抽籤的形式隨機決定「驗證者」,並以帶有權重的方式來全網共識,可認爲是 BFT 類共識+PoS 或 PoWeight 的架構。投票過程分爲兩個階段:第一階段通過一個分級共識選出「驗證者」共識最多的候選區塊;第二階段運行一個二元拜占庭協議(接受出塊或產生空塊)。執行速度很快,不太容易產生分叉且交易確認時間雖用戶數增加變化不大 [33]。另外,Algorand 通過加密方式隱藏了「領導者」的真實身份,提高了針對 Leader 攻擊的安全性。
VBFT 協議也是使用 VRF 的一個共識協議 [47],由 Ontology 提出,可認爲是 PoS+VRF+BFT:在共識協議的各個階段,分別使用 VRF 從網絡中選出該階段所需要的節點,例如提案節點、驗證節點、確認節點等並完成最終的共識。其中的選擇參數是根據 PoS 來確定。
門限簽名
以上介紹的協議大部分都需要假設基於一個同步或半同步的網絡環境,而 HoneyBadger BFT 是第一個知名的異步 BFT 類協議 [48],可在消息延遲沒有明確上限的異步網絡中運行。它首先將交易拆分爲多份,各個節點間相互,減輕發起節點的消息發送瓶頸問題。而因爲其異步網絡環境,節點間收到交易是非同步的、隨機順序的。節點以二元拜占庭協議剔除無效交易和重複交易等後,得到一個異步公共交易子集(Asynchronous Common Subset)[49]。
而門限加密使得只有 f+1 個誠實節點共同合作才能解密出消息原文,防止惡意節點對於最終交易集的攻擊。HoneyBadger BFT 協議的主要限制是其在異步網絡下爲一個非確定性共識算法(FLP 不可能性原理 [25])。
5. 實測對比
除了進行理論上的歸納總結與分析外,我們選用 PBFT、Zyzzyva、Zilliqa 協議,編寫共識協議的程序進行實測模擬。通過橫向與縱向的測試比較,以期得出以上共識協議的技術建議。
5.1. 測試方案介紹
由於共識協議都需要基於一個實際的應用場景,我們在程序中將節點處理計算的過程設定爲一個固定的延時;消息傳輸採用消息隊列方式來實現。程序基於 Java 8 編寫實現。
因爲 PBFT、Zilliqa 等共識協議在一些實現細節上缺少明確描述,我們在實現程序時進行了以下設定:
1)節點之間的網絡時延在 5-10 毫秒內
2)網絡帶寬設置爲 100MB (假設每條請求消息平均 100B 大小)
5.2. 場景 1:節點均正常的橫向比較
首先在所有節點均爲誠實節點的情況下,我們進行多組實測,橫向比較 PBFT、Zyzzyva、Zilliqa 共識協議在不同情況下的協議吞吐量、網絡中平均消息量、達成共識總時長等性能指標。
本場景的第 1 組測試條件爲:
1)批量大小 = 10
2)水位大小 =30
3)檢查點週期 =10
4)客戶端數量 =1,消息發送間隔 =1ms
橫向比較的結果(其中吞吐量和網絡平均消息量單位均爲消息筆數,下同)如下:


整體來看,BFT 類協議的吞吐量確實均會隨着節點數增加而下降(性能降低),當節點數量過多時,很難完成處理。
對於 PBFT 協議,可看到其消息量和節點數量確實有平方級的關係(本例中約爲 6*n^2);
而 Zyzzyva 和 Zilliqa 的消息量爲線性關係,即以上協議的方法確實會降低 PBFT 消息量大的問題。
由於批量大小會影響網絡中處理消息的數量,因此我們在第 2 組觀察批量大小對性能的影響。測試條件爲:
1)節點數 =22
2)水位大小 =30
3)檢查點週期 =10
4)客戶端數量 =1,消息發送間隔 =1ms

從結果可以看出,增加批量大小對吞吐量均有較爲明顯的提升,但也會增加網絡中的消息量。其中,Zilliqa 的吞吐量提升最爲明顯,因爲該算法可以在一個單位時間內進行聚合簽名並且可以批量驗證,即批量大小相當於打包區塊的大小。所以當總帶寬允許的情況下,Zilliqa 算法可以通過增加批量而獲取極大的吞吐量。
PBFT 和 Zyzzyva 提升到一定階段後在實測中會遇到瓶頸(批量數 >30 後,吞吐量始終接近 1000),原因是本次測試客戶端消息間隔導致。如果降低發送間隔或者增加客戶端數量均可提高吞吐量。例如,當假設消息可並行處理且沒有到達網絡帶寬瓶頸,增加客戶端可得到如下 PBFT 的性能結果爲:

5.3. 場景 2:節點異常時的橫向比較
BFT 類協議的一個複雜之處在於部分節點存在拜占庭行爲情況下的處理,各個協議對不同數量的異常節點,該情況下的效率可能也不一樣。
在本場景中我們設置節點數固定爲 22 個。
本場景第 1 組測試設置條件爲:
1)批量大小 =10
2)水位大小 =30
3)檢查點週期 =10
4) 客戶端數量 =1
經過測試 PBFT、Zyzzyva、Zilliqa 的吞吐量分別爲:

其中,可看到 PBFT 吞吐量和共識時間都優於 Zyzzyva 和 Zilliqa,是因爲本次測試暫忽略了網絡消息量增大對消息傳播延遲的影響。
從結果也可看到網絡平均消息量會減小,尤其是 PBFT 的消息量會隨着節點增多而降低較快。其原因是當出現拜占庭節點時,作惡節點的消息會被忽略掉;而同時,消息傳播和達成共識的時間會相應延長。
5.4. 場景 3:PBFT 測試研究
下面的幾個場景我們對比 PBFT 的批量、檢查點週期與吞吐量、網絡中平均消息量以及達成共識時間等性能表現之間的關係。
1)節點數 =22
2)水位大小 =50


可以看到,對於 PBFT 來說,檢查點週期調整對性能的影響並沒有太大;而調整批量大小則會較大程度上提高吞吐量指標、縮短共識時間,不過同時也會加大消息量對網絡造成壓力。
5.5. 場景 4:Zyzzyva 測試研究
從上述場景已可看到,調整批量大小會對共識性能產生影響;而 Zyzzyva 的主節點負責接收各客戶端發來的請求,因此在客戶端數量不同的情況下,表現可能也會不一樣。因此我們針對不同的批量大小和客戶端數量進行分析研究。


從結果可以看到,當批量數較小時,增加客戶端數量後,Zyzzyva 整體性能並沒有太大改觀。
當增大批量後,Zyzzyva 的吞吐量提高較爲明顯;在增加客戶端數量後,吞吐量和共識時間均有改觀,但在增加一定程度後其表現並不會繼續提升。
另外和 PBFT 類似,增加客戶端數量或增大批量後,Zyzzyva 的網絡消息也會隨之增加。
5.6. 場景 5:Zilliqa 測試研究
從場景 1 的測試中可看出,Zilliqa 的 Batch 可以設置的遠比 PBFT 大從而獲得極大的吞吐量,因此與前兩個縱向對比測試略有不同,本場景測試着眼點在網絡帶寬消耗上。在不同 Batch 下,我們測試研究 Zilliqa 的消耗情況(以 PBFT 作爲一個基準對比)。
測試條件爲:
1)節點數 =22
2)檢查點週期 =10
3)消息大小 =100B

可以看到,儘管可設置較大的批量數來獲得更高的吞吐量,但 Zilliqa 的最大帶寬消耗也會隨着批量數而線性增長。作爲對比,PBFT 在批量數到達一定數量後,最大消耗帶寬會趨於穩定。因此在實際應用共識協議時,應充分考慮好選用的共識協議以及實際網絡帶寬情況。
6. 參考資料
[1] M. van Steen and A. S. Tanenbaum,Distributed Systems, 3.01. 2017.
[2] S. Gilbert and N. Lynch, “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services,”ACM SIGACT News, 2002.
[3] S. Gilbert and N. Lynch, “Perspectives on the CAP Theorem,”Computer (Long. Beach. Calif)., vol. 45, no. 2, pp. 30–36, 2012.
[4] L. Lamport, R. Shostak, and M. Pease, “The Byzantine Generals Problem,”ACM Trans. Program. Lang. Syst., 1982.
[5] LoomNetwork, 「瞭解區塊鏈的基本(第一部分):拜占庭容錯 (Byzantine Fault Tolerance),」2018. [Online]. Available: https://segmentfault.com/a/1190000014009235.
[6] bangerlee, “[上篇] 大話分佈式系統理論基礎 .” [Online]. Available: https://mp.weixin.qq.com/s/p4PEZPjxJyYXKpkCCdShbw.
[7] 初夏虎 , “拜占庭將軍問題深入探討 ,” 2015. [Online]. Available: https://www.8btc.com/article/70370.
[8] V. Buterin, “A Guide to 99% Fault Tolerant Consensus,” 2018. [Online]. Available: https://vitalik.ca/general/2018/08/07/99_fault_tolerant.html.
[9] 袁煜明 and 胡智威 , “【火線視點 10】Vitalik 的‘99% 容錯共識算法’解析 .”
[10] D. Gupta, L. Perronne, and S. Bouchenak, “BFT-Bench: Towards a practical evaluation of robustness and effectiveness of BFT protocols,” inLecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2016.
[11] J. FAN, L.-T. YI, and J.-W. SHU, “Research on the Technologies of Byzantine System,”J. Softw., vol. 24, no. 6, pp. 1346–1360, 2014.
[12] M. Castro and B. Liskov, “Practical byzantine fault tolerance and proactive recovery,”ACM Trans. Comput. Syst., 2002.
[13] R. van Renesse and F. B. Schneider, “Chain Replication for Supporting High Throughput and Availability,”Proc. 6th Conf. Symp. Opearting Syst. Des. Implement. – Vol. 6, 2004.
[14] P.-L. Aublin, R. Guerraoui, N. Knežević, V. Quéma, and M. Vukolić, “The Next 700 BFT Protocols,”ACM Trans. Comput. Syst., vol. 32, no. 4, pp. 1–45, 2015.
[15] R. Guerraoui, N. Knezevic, V. Quema, and M. Vukolic, “Stretching BFT,” 2010.
[16] A. Bessani, J. Sousa, and E. E. P. Alchieri, “State machine replication for the masses with BFT-SMART,” inProceedings – 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, DSN 2014, 2014.
[17] A. Clementet al., “Upright cluster services,” inProceedings of the ACM SIGOPS 22nd symposium on Operating systems principles – SOSP ’09, 2009.
[18] Wikipedia, “Quorum (distributed computing).” [Online]. Available: https://en.wikipedia.org/wiki/Quorum_(distributed_computing).
[19] M. Abd-El-Malek, G. R. Ganger, G. R. Goodson, M. K. Reiter, and J. J. Wylie, “Fault-scalable Byzantine fault-tolerant services,” inProceedings of the twentieth ACM symposium on Operating systems principles – SOSP ’05, 2005.
[20] B. Bershad, D. ACM Digital Library., B. ACM Special Interest Group in Operating Systems., R. Rodrigues, and L. Shrira, “HQ Replication: A Hybrid Quorum Protocol for Byzantine Fault Tolerance,”Proc. 7th Symp. Oper. Syst. Des. Implement., p. 407, 2006.
[21] R. Kotla, L. Alvisi, M. Dahlin, A. Clement, and E. Wong, “Zyzzyva: Speculative Byzantine Fault Tolerance,”Proc. Symp. Oper. Syst. Princ., pp. 45–58, 2007.
[22] A. Singh, P. Fonseca, and P. Kuznetsov, “Zeno: Eventually Consistent Byzantine-Fault Tolerance.,”Nsdi, pp. 169–184, 2009.
[23] T. Wood, R. Singh, A. Venkataramani, P. Shenoy, and E. Cecchet, “ZZ and the art of practical BFT execution,” inProceedings of the sixth conference on Computer systems – EuroSys ’11, 2011.
[24] A. Shoker, J. P. Bahsoun, and M. Yabandeh, “Improving independence of failures in BFT,” inProceedings – IEEE 12th International Symposium on Network Computing and Applications, NCA 2013, 2013.
[25] M. J. Fischer, N. A. Lynch, and M. S. Paterson, “Impossibility of distributed consensus with one faulty process,”J. ACM, 1985.
[26] R. Kapitzaet al., “CheapBFT: Resource-efficient Byzantine Fault Tolerance,”Proc. 7th ACM Eur. Conf. Comput. Syst., 2012.
[27] J. Hendricks, S. Sinnamohideen, G. R. Ganger, and M. K. Reiter, “Zzyzx: Scalable fault tolerance through Byzantine locking,” inProceedings of the International Conference on Dependable Systems and Networks, 2010.
[28] A. Clement, E. Wong, L. Alvisi, M. Dahlin, and M. Marchetti, “Making Byzantine Fault Tolerant Systems Tolerate Byzantine Faults,”Symp. A Q. J. Mod. Foreign Lit., 2009.
[29] Y. Amir, B. Coan, J. Kirsch, and J. Lane, “Prime: Byzantine replication under attack,”IEEE Trans. Dependable Secur. Comput., 2011.
[30] G. S. Veronese, M. Correia, A. N. Bessani, and L. C. Lung, “Spin one’s wheels? Byzantine fault tolerance with a spinning primary,” inProceedings of the IEEE Symposium on Reliable Distributed Systems, 2009.
[31] P. L. Aublin, S. Ben Mokhtar, and V. Quema, “RBFT: Redundant byzantine fault tolerance,” inProceedings – International Conference on Distributed Computing Systems, 2013.
[32] R. Pass and E. Shi, “Hybrid consensus: {Efficient} consensus in the permissionless model,”Leibniz {Int}. {Proc}. {Informatics}, {LIPIcs}, 2017.
[33] 姚前 , 數字貨幣初探 . 中國金融出版社 , 2018.
[34] “Graphene Technical Documentation.” [Online]. Available: http://docs.bitshares.org/.
[35] “BitShares Whitepapers.” [Online]. Available: http://docs.bitshares.org/bitshares/papers/.
[36] “Steem Whitepaper.” [Online]. Available: https://steem.io/steem-whitepaper.pdf.
[37] “EOS.IO Technical White Paper v2.” [Online]. Available: https://github.com/EOSIO/Documentation/blob/master/TechnicalWhitePaper.md.
[38] NEO, “A Byzantine Fault Tolerance Algorithm for Blockchain.” [Online]. Available: http://docs.neo.org/en-us/basic/consensus/whitepaper.html.
[39] “Cosmos Whitepaper.” [Online]. Available: https://github.com/cosmos/cosmos/blob/master/WHITEPAPER.md.
[40] C. Unchained, “Tendermint Explained — Bringing BFT-based PoS to the Public Blockchain Domain.” [Online]. Available: https://blog.cosmos.network/tendermint-explained-bringing-bft-based-pos-to-the-public-blockchain-domain-f22e274a0fdb.
[41] Z.-C. Lin, “Istanbul BFT (IBFT).” [Online]. Available: https://medium.com/getamis/istanbul-bft-ibft-c2758b7fe6ff.
[42] H. Hashgraph, “Hedera: A Governing Council & Public Hashgraph Network.” [Online]. Available: https://s3.amazonaws.com/hedera-hashgraph/hh-whitepaper-v1.1-180518.pdf.
[43] E. Kokoris-Kogias, P. Jovanovic, N. Gailly, I. Khoffi, L. Gasser, and B. Ford, “Enhancing Bitcoin Security and Performance with Strong Consistency via Collective Signing,” 2016.
[44] T. Z. Team, “Zilliqa Technical Whitepaper,”Zilliqa, pp. 1–8, 2017.
[45] P. Li, G. Wang, X. Chen, and W. Xu, “Gosig: Scalable Byzantine Consensus on Adversarial Wide Area Network for Blockchains,” 2018.
[46] Y. Gilad, R. Hemo, S. Micali, G. Vlachos, and N. Zeldovich, “Algorand: Scaling byzantine agreements for cryptocurrencies,”Proc. 26th Symp. Oper. Syst. Princ., 2017.
[47] “VBFT 算法介紹 .” [Online]. Available: https://github.com/ontio/documentation/blob/master/vbft-intro/vbft-intro-CN.md.
[48] A. Miller, Y. Xia, K. Croman, E. Shi, and D. Song, “The Honey Badger of BFT Protocols,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security – CCS’16, 2016.
[49] Juniway, “Honey Badger of BFT 協議詳解 .” [Online]. Available: https://www.jianshu.com/p/15d5b6f968d9.
來源鏈接:www.jianshu.com