
規模經濟總是普遍存在的 —— 不管是從成本角度,還是經驗角度。對於 ASIC 芯片設計成本, 芯片設計師們似乎總是存在很大爭論,本文由 ProgPoW 背後的算法開發團隊 IfDefElse 爲大家詳細解讀受到業內關注的九個問題。
原文標題:《深挖 ASIC 芯片設計成本,我們問了 ProgPoW 核心開發團隊九個問題》
原文作者:IfDefElse,ProgPow 算法開發團隊
文章來源:Medium 翻譯:Moni
概述
只要與 ProgPow 和 Ethash 算法有關,市場上就會出現各種對礦機硬件設計和開發成本的推測,通常後面還會跟上一個權威聲明:請相信發表預測的作者,因爲他 / 她在相關行業領域裏擁有豐富經驗。這些推測有時會與加密貨幣 ASIC 芯片生產有關,還有些時候則是關於集成電路設計。
對於那些更熟悉代碼、卻不太瞭解扇出(fan-out)和上升時間(rise-times)的讀者來說,本文可能會對他們深入瞭解 ProgPoW 算法有所幫助。
(注:Ethash 是目前以太坊基於工作量證明的挖礦共識算法,ProgPoW 是一個試圖削弱 ASIC 礦機優勢的挖礦算法。扇出是一個定義單個邏輯門能夠驅動的數字信號輸入最大量的專業術語。大多數的 TTL 邏輯門能夠爲 10 個其他數字門或驅動器提供信號,因此一個典型的 TTL 邏輯門有 10 個扇出信號;上升時間是脈衝技術裏的一個專業名詞,電壓上升兩個時刻的時間間隔就是網絡變壓器的上升時間。)
程序員總是會給人一種無所不能的感覺,從編寫腳本到開發 iPhone APP,從嵌入式系統到 Windows 操作系統。但是,會寫代碼開發應用程序不代表你能成爲 APP Store 應用商店後端(或改善系統效率)的權威人士,能夠開發實時多任務操作系統(RTOS)也不代表你能成爲擴展 Windows 操作系統成本權衡領域裏的達人。
當然,作爲 ProgPoW 算法核心開發團隊,IfDefElse 在此並不是說 Windows 設計師不是「優秀的程序員」,但必須要說明的是,由於不同人的技術背景不同,很容易造成對不同領域的理解和假設偏差,特別是在討論規模經濟話題的時候。
同樣地,一名硬件設計師可能也會涉獵不同的領域,比如爲一款電動牙刷設計芯片,或是爲網絡設備構建一個芯片架構(silicon architect)。生產 10 萬個電動家牙刷芯片的工程師可能不會理解生產 100 萬個芯片的網絡工程師所考慮的可用規模經濟,同樣一個加密貨幣 ASIC 芯片設計師可能對 GPU-ASIC 芯片設計知之甚少 —— 這些行業彼此之間的聯繫並不是很多,有的甚至是國與國之間的差距。
在概述中我們還要提的最後一點,就是編程和工程其實都是一種技巧,除非你每天都在編程寫代碼,否則很快就會落後、無法成爲權威,因爲這方面的知識更新迭代很快。或許這也是爲什麼新的加密貨幣 ASIC 製造商很難進入基於 SHA-256 算法的挖礦市場,畢竟一個新手程序員想要趕超已經研究 SHA-256 算法六年的工程師是不太可能的。
另一方面,加密貨幣生態系統裏其實並沒有太多文章介紹硬件知識。當然,加密貨幣本身就是一個以軟件爲主導的行業,而且絕大多數硬件工程都是在一些私人公司內部「閉門」研究的。
有些「硬件磚家」正在竭盡全力向軟件工程師保證他們能夠戰勝加密貨幣生態系統 —— 我們已經在門羅幣(Monero)、比特幣(Bitcoin)、以及 ZCash 等加密貨幣上看到了這種情況已經出現。但現實是,這種挑戰至今仍沒有發生,想想看,如果比特大陸或 Innosilicon 試圖製造 CPU,你認爲他們能夠戰勝英特爾和 AMD 嗎?
規模經濟總是普遍存在的——不管是從成本角度,還是經驗角度。對於 ASIC 芯片設計成本, 芯片設計師們似乎總是存在很大爭論,下面我們團隊就爲大家詳細解讀一下受到業內關注的九個問題:
問題一:不管挖礦算法是 ProgPoW,還是 ETHash,哈希值都是由外部動態隨機存取存儲器(DRAM)的存儲帶寬決定的,是這樣嗎?
事實並非如此。ProgPoW 的哈希值是由兩個因素決定的:
- 計算核心
- 內存帶寬
這就是爲什麼 Ethash 和 ProgPoW 之間存在差異,如下圖 1 和圖 2 所示:
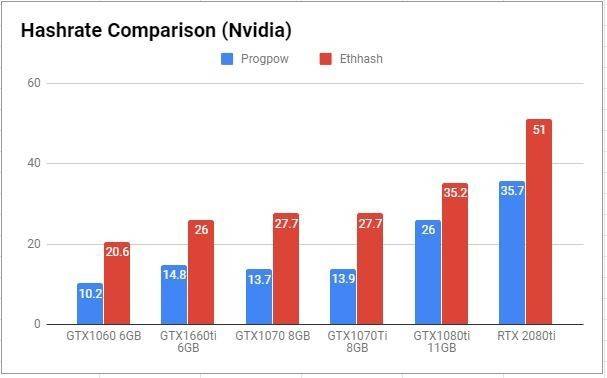 圖 1 :英偉達芯片產品挖礦哈希率比較
圖 1 :英偉達芯片產品挖礦哈希率比較
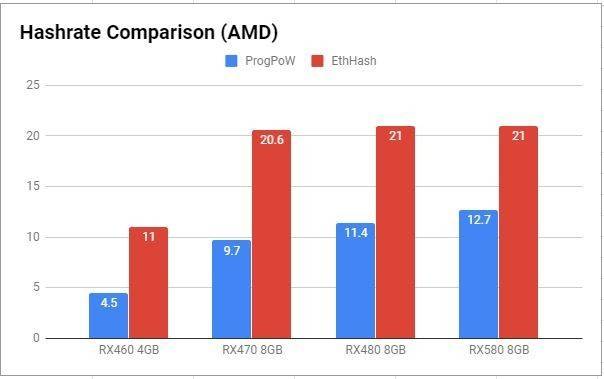 圖 2 :AMD 芯片產品挖礦哈希率比較
圖 2 :AMD 芯片產品挖礦哈希率比較
現階段,ETHash 挖礦更有利可圖,針對該算法的內存需求明顯增加,對於高帶寬存儲器的需求不斷增長也促使下一代高速存儲器技術被開發了出來,比如 GDDR6 (帶寬速度達到 768 GB/s) 和 HMB2 (帶寬速度達到 256 GB/s)。
對於高帶寬內存的需求並非全部來自「Ethash」,整個高帶寬內存市場規模高達 150 億美元,其中只有很少一部分來自採礦行業。高帶寬內存的核心市場需求主要包括:GPU、現場可編程門陣列(FPGA)、人工智能(AI)、高性能計算(HPC)、以及遊戲。相比於 1.2 萬億美元的人工智能市場、300 億美元的 PC 遊戲市場、350 億美元的手持遊戲機市場、以及 290 億美元的高性能計算市場,挖礦行業的高帶寬內存需求真的是「微不足道」。
問題二:由於 ProgPoW 現有架構和算法與 ETHash 存在相似之處,Innosilicon 的下一款 ASIC 芯片將會爲 ProgPoW 量身定製嗎?
事實上,ProgPoW 和 ETHash 之間唯一的相似之處就是在全局內存(global memory)中使用了無環圖(DAG)。從計算的角度來看,ETHash 只需要一個固定的「keccak_f1600」內核和一個模數函數(modulo function)。另一方面,ProgPoW 需要的則是能夠執行 16 通道寬的隨機數學序列,同時還要能夠訪問高帶寬一級緩存(L1 cache)。設計一個能夠執行 ProgPow 數學序列的計算內核,比設計一個能夠實現類似「keccak」這樣的固定函數哈希要難得多。
另外需要注意的是,ETHash 的哈希值只取決於內存帶寬,而 ProgPoW 算法則同時取決於內存帶寬和隨機數學序列的核心計算——理解這一點非常重要。
工作量證明(PoW)的本質其實是通過耗費硬件和能源成本進行數學計算證明,作爲一種算法,ETHash 在數學證明中並不會耗費大部分硬件費用(計算引擎)。相反,ETHash 只捕獲內存接口,這就是爲什麼你可以使用一個用於加密貨幣挖礦的 ASIC 芯片來把數學計算中沒有被捕獲到的部分給消減掉。
問題三:由於 GPU 是通用加速芯片,因此設計、製造和測試 GPU 的週期通常需要大約十二個月,而且還需要進行大量硬件模擬和軟件開發工作,使其能夠覆蓋不同的計算方案和場景。
ProgPoW 希望能夠捕獲全部硬件成本(儘可能地做到),由於該算法更新的部分能夠捕獲運行不同計算場景的計算硬件——直到架構褶皺(architectural wrinkles) —— 因此對於 ASIC 芯片設計來說,可能需要耗費不止 3-4 個月的時間。
由於時間跨度較長,隨之會引發出另一個問題:爲什麼浮點運算(floating point operation)被省略掉了?這個問題的答案其實也非常簡單:浮點運算不能跨芯片移植,不同芯片往往會以不同方式來處理與特殊值(比如下確界、非數字數值、以及相關變體等)相關的邊界案例(corner case)。邊角案例也被成爲病態案例(pathological case),是指其操作參數在正常範圍以外的問題或是情形,而且多半是幾個環境變數或是條件都在極端值的情形,即使這些極端值都還在參數規格範圍內(或是邊界)。其中最大的分歧在於非數字數值(NaN)的處理,這會在使用隨機輸入時自然發生,引用維基百科頁面的解釋:
如果有多個非數字數值(NaN)輸入,其有效負載結果應該來自其中一個非數字數值輸入,但標準卻沒有具體說明。
這意味着,如果要使用浮點運算的話,基本上每個浮點都需要進行「if (is_special (val)) val = 0.0」檢查配對,這種檢查通常可以在硬件中完成,因此也會讓用於加密貨幣挖礦的 ASIC 芯片從中受益。
接下來,哈希率(Hashrate)和「hash-per-watt」又是什麼呢?
哈希率是衡量能源成本的指標,只要每個人都以同樣的方式進行衡量,每單位的能源消耗就不那麼重要——礦工也會繼續投入儘可能多的能源挖礦。不過即便你把測量單位從 1 ETHash (較小單位,比如焦耳)切換成 1 ProgPoW-hash (較大單位,比如卡路里),運營成本的經濟性其實也不會發生變化。全局哈希率(Global Hashrate)會評估每個人對保護網絡共享的總經濟權重,只要每個人的貢獻都被公平地衡量且使用相同的單位,對於普通礦工來說,切換到 ProgPoW 算法不會帶來什麼變化。
當然,有人會說如果以太坊實施了 ProgPoW 算法可能會有助於把礦工集中在擁有高端 GPU 的大礦場裏,同時也會刺激礦場把 GPU 升級到最新型號。但是 ProgPoW 算法開發團隊 IfDefElse 需要再次重申的是:規模經濟永遠都會存在,而且也是現實世界裏無法避免的事實。
問題四:相比於 GPU,ASIC 芯片生產商可以使用較小的 GDDR6 內存來獲得成本優勢。在保持內存成本水平的同時,16 個 GDDR6 4GB 的內存條能夠實現兩倍的帶寬優勢,是這樣嗎?
首先,擁有兩倍的帶寬優勢就需要兩倍的計算,這其實是一種線性擴容(linear scaling),並不能看做是一種優勢。
其次,我們目前應該還沒有爲 GDDR6 準備好生產 4GB 內存芯片的準備。全球第三大內存芯片廠商 Micron (美國美光)只生產 8GB 芯片,三星則生產 8 GB 和 16 GB 芯片。對於內存芯片而言,GDDR6 IO 接口區域是非常昂貴的,而且與存儲器單元相比,每一代接口都佔用了更多的實際存儲器管芯,由於端口物理層(PHY)不能像存儲器單元那樣通過工藝手段縮小。
不可否認,真正推動內存市場的是一些「長週期買家」,比如遊戲機、GPU 等,他們也傾向於支持容量更大的內存。事實上,如今的內存供應商沒有動力去大批量生產一個 4GB 的內存,畢竟市場對這種內存容量的需求並不大。
問題五:RTX2090 芯片中有許多模塊佔用了大量芯片模片區面積,而且對 ProgPoW 毫無用處,包括 PCIE、NVLINK、L2Cache、3072 分片單元、64 個 ROP、192 個時間測量單元(TMU)等,如何看待這個問題?
RTX2080 不是討論這個問題的好參照物,由於一些新功能,英偉達(Nvidia)的 RTX 系列芯片中有些模塊佔據了大部分芯片模片區面積,比如光線追蹤核心等。ProgPoW 設計則是與英偉達和 AMD 生態系統中的存量芯片產品搭配使用的,因此無法使用英偉達和 AMD 新款芯片產品中的新功能。
如果想有一個更好類比的話,或許 AMD RX 5xx 系列或是英偉達 GTX 1xxx 系列是個不錯的參照。正如我們之前所述,GPU 中也有部分功能沒有被 ProgPoW 利用,比如:浮點邏輯、二級(L2)緩存、以及紋理緩存和 ROP 等。分片單元是向量數學被執行的地方,這絕對是 ProgPoW 所要求的。用於加密貨幣挖掘的 ASIC 芯片還希望添加能夠實現「keccak」功能的區域。作爲 ProgPoW 算法的開發團隊,我們估計 ProgPoW ASIC 芯片的模片區面積會比同等 GPU 小 30%——但是,即便是在最好的情況下,其功耗最多也只會降低 20%。相比之下,雖然 GPU 上有些邏輯模塊沒有被充分應用而造成部分芯片模片區面積浪費,但功耗卻是最小的。
問題六:與大芯片相比,小芯片的收益會更高嗎?
怎麼說好呢,這聽上去像是在普及芯片製造知識,或許我們需要寫一篇《芯片製造 101》的培訓文檔。此外,對於收益計算公式可以參考一篇 2006 年發表的文章《Compare Logic-Array To ASIC-Chip Cost per Good Die》,其中你會發現,早在 13 年之前芯片收益和流程控制就已經有很大創新了。
對於具有單個功能單元的芯片,模片區面積較小的芯片收益會比模片區面積較大的芯片更高。但是對於現代 GPU 來說,情況並非如此。如今的 GPU 幾乎可以任意恢復、組合,小型複製單元的缺陷基本上可以忽略。只要每個可壓縮功能單元足夠小,那麼 GPU 芯片收益幾乎可以和功能模塊更大的芯片一樣高(甚至更高)。
爲了更好地解釋這個概念,我們可以舉一個簡單的腦洞實驗:
1)假設你有一個大芯片「Giant ChipA」,它佔據了整個晶片。這個「Giant ChipA」是由 10 萬個可拆卸子組件組成,但是其中必須確保 80% 的子組件是無缺陷的,才能保證「Giant ChipA」正常工作,而在嵌入過程中,壞的子組件會被繞過;
2)另外,假設你還有一個小芯片「Tiny ChipB」,它只有一個功能模塊(不可嵌入)組成,但是這個小芯片卻小到足以在同一個晶片上裝配 10 萬個子組件。在這種情況下,只要一個子組件壞了,意味着整個「Tiny ChipB」芯片就是壞的;
3)如果每個晶片上平均分佈了 2 萬個有缺陷的子組件,那麼「Giant ChipA」的收益可以爲 100%,因爲他們可以將 20% 有缺陷的子組件拆掉,而「Tiny ChipB」的收益可能僅爲 80%,因爲他們無法拆掉有缺陷的子組件。
如果你看看 AMD 的 Polaris 20 系列產品和英偉達的 GP 104 產品,會在模擬鏡頭下發現這些 GPU 中部署了大量微小的「可拆卸」子模塊組成。
問題七:ASIC 礦機電壓可以很輕鬆地降低到 0.4V,只有 GPU 的二分之一 … 這樣低電壓的 ASIC 設計已經被比特幣挖礦設備 ASIC 礦機制造商所採用,所以現在我們沒有理由不相信他們不會把這種策略應用在 ProgPoW ASIC 礦機上,能談談這個問題嗎?
當芯片僅由計算構成,那麼低電壓設計才能奏效,比如一個專門針對 SHA256d 挖礦算法計算的 ASIC 礦機。集成其他原件——比如 SRAM,這也是 ProgPoW 數據緩存所必需的——的難度極大,也不可能在低電壓下工作。
問題八:同樣的節能效果也能在 LPDDR4x DRAM 上實現,其功耗比 GDDR6 還低,談談這個問題吧。
不能僅考慮能耗問題,LPDDR4x 的帶寬比 GDDR6 低很多,前者每個引腳帶寬是 4.2Gb / s,後者則是 16Gb / s。LPDDR4x 計算芯片上需要四倍的內存芯片和四倍的內存接口才能達到 GDDR6 相同的性能,這樣一算,其成本其實是顯著增加的。
值得注意的是,高帶寬計算芯片的接口通常是有限的,這意味着芯片模塊面積必須要足夠大,周邊幾乎不允許任何信號從芯片脫落到印製電路板(PCB)上,LPDDR4x 設計需要大約四倍的芯片周長焊盤數才能達到相同的帶寬,也就是說,其成本不僅僅在存儲芯片上,計算芯片區域的成本同樣也要計算在裏面,所以綜合算下來其實總成本並不低。更糟糕的是,由於任何芯片都是以速度爲導向的,當芯片模塊面積更大的時候,意味着浪費的功率也會更多。
所以,不妨讓我們再想想爲什麼如今的 GPU 不能再 LPDDR4x 上運行。首先,LPDDR4x 在帶寬成本上的表現並不盡如人意,對於給定的帶寬量級(芯片數量的四倍),LPDDR4x 的成本要高出四倍以上,繼而導致成本顯著增加——LPDDR4x 在 9W 功率時 256 GB/s 帶寬的成本約爲 150 美元,相比之下 GDDR6 在 11W 功率時同樣帶寬成本還不到 40 美元,因此 LPDDR4x 並沒有讓礦工省到什麼錢(注意,這裏說的是帶寬成本,而不是內存容量成本)。
問題九:像英偉達這樣的 GPU 生產商僱傭了大約 8000 人來開發 GPU,這些 GPU 也非常複雜;而像 LinZhi 這樣的 ASIC 生產商只僱傭了十幾個人,而且只開發用於 ETHash 挖礦算法的 ASIC 礦機。這些公司的勞動力成本相差 100 被,因此可不可以說 ASIC 芯片在成本和上市時間方面比 GPU 芯片更具優勢。
在此要說的是,規模經濟是一個重要因素。GPU 行業也是在全球各種銷售渠道中攤銷,目前總市場規模大約爲 4200 億美元,其中 AMD 市值約爲 116 億美元,英偉達約爲 1545 億美元,最大的英特爾約爲 2548 億美元。僅就內存市場而言,還需要在這個總規模達到 5000 億美元的行業裏分攤物理端口(PHY)和晶片的成本,其中擁有 320,671 名員工的三星電子市值約爲 3259 億美元,他們也是在美國最活躍的專利申請者;第二名是擁有 34,100 名員工的 Micron Technology,其市值約爲 601 億美元,但是第一個開發出 20Gbps 高速 GDDR6 內存的芯片製造商;海力士擁有 187,903 名員工,市值約爲 568 億美元,他們開發了全球首款 1Ynm 16Gb DDR5 DRAM。相比之下,用於加密貨幣挖礦的 ASIC 芯片行業總市值不過 1460 億美元,其中 730 億屬於比特幣。
另外我們還要看看上市時間和技術接受模型(TAM),在此不妨以著名的 S9 礦機繼任者開發時間作爲參考。如果經過充分研發、並且計算難度不是很高的 SHA256d 算法計算芯片都需要耗費三年時間才能進行迭代,那麼又有什麼可以保證像 GPU 一樣的、支持 ProgPoW 算法的 ASIC 礦機快速投產上市呢?我們還可以分析一下最近挖掘以太坊加密貨幣的 ASIC 礦機情況,GDDR6 芯片樣品試用期已經有一年時間了,到目前仍然沒有發佈能夠被廣泛應用的新版本產品。
ProgPoW 核心開發團隊 IfDefElse 的最後一點想法
ProgPoW 其實針對是一種挖礦硬件,這種硬件受到了規模經濟的支持,具有高可見性並獲得了較大競爭優勢。
ProgPoW 核心開發團隊 IfDefElse 規模並不大,而且團隊成員也都有全職工作,所以他們無法及時回覆所有問題和文章,更沒時間在各種加密貨幣和區塊鏈線上論壇裏喋喋不休。雖然 IfDefElse 對硬件設計和開發非常感興趣,但他們仍然建議涉足這一領域的人需要保持謹慎,因爲硬件和軟件一樣,是一個多元化的領域,即便你是一個對加密貨幣挖礦 ASIC 芯片非常熟悉的大咖,但在 GPU-ASIC 領域裏可能無法成爲一個專家。
來源鏈接:medium.com